AI SIMPLY EXPLAINED
All You Need To
Know About AI
Enhancing Generative AI with Vector Databases: Part One
This is Part 1 in a two-part series of how to build your vector database from scratch. Jump to Part 2 if you know these underlying concepts.
We are aware of the all-knowing, powerful ChatGPT, but have you wondered what could make it even more powerful? If you guessed giving it memories, then you are right. Data is the strongest weapon you can give a large language model (LLM), and if it were provided with the data of its memories, the possibilities would expand exponentially. Imagine ChatGPT not just recalling its training data but also accessing a dynamically updated repository of knowledge - a memory bank that grows and evolves over time. (refer to this article to learn more about LLMs with memory) This is where the magic of vector databases comes into play.

The Blueprint of AI Memories: Vector Embeddings
To equip an LLM like ChatGPT with memories, we need a data structure that transcends traditional databases. The journey begins with the transformation of words into an array of numbers - a process known as vector embedding. To understand why we convert words into numbers, let's delve into the intricacies of vector embeddings and their significance.
The Why: Numerical Language of AI
Human language is rich, nuanced, and incredibly complex. It conveys not just facts, but emotions, irony, and a spectrum of meanings that can change with context. For a computer, which operates on binaries and quantifiable data, this richness presents a challenge.
Imagine trying to explain the color "blue" to someone who has been blind from birth — you'd have to translate visual stimuli into something they can understand through touch or sound. Similarly, we need to translate the 'color' and 'texture' of language into a 'language' that AI can understand. This translation is achieved through vector embeddings. But how does one turn the abstract, nuanced nature of language into a quantifiable format?
The How: Crafting the Vectors
Vector embeddings transform words into multi-dimensional vectors, or arrays of numbers, where each dimension corresponds to a latent feature of the word. These features are not handpicked but are learned from data. The process is somewhat akin to an artist learning to mix colors to create the right shade; the machine learns to mix features to create the right vector.
Word Embedding Models
Word embedding models like Word2Vec, GloVe, and FastText are algorithms that process large corpora of text and learn to assign a dense vector to each unique word. These vectors capture syntactic and semantic similarities based on the context in which words appear. For instance, in the vector space, words like "king" and "queen" will have vectors pointing in similar directions because they often appear in similar contexts and share relational meanings.
Semantic Search: Finding Meaning Beyond Keywords
With these vectors as our foundation, we can revolutionize how ChatGPT searches for information. Unlike the rigid keyword searches of yesteryear, semantic search understands context and nuance. It's like a librarian who knows not just the titles of books but their content and context, guiding you to the right knowledge by understanding the essence of your query.

Enter the concept of cosine similarity. Imagine each word as a point in space, and the meaning of the word defined by its position relative to all other words. Cosine similarity measures the cosine of the angle between two such points (or word vectors) in multidimensional space. When the cosine value is close to 1, it indicates that the angle between the vectors is small, and the words share a strong semantic relationship. Conversely, a cosine value near 0 implies orthogonality, denoting little to no semantic similarity.

By leveraging this method, we ensure that our AI can discern and recognize that words like "astute" and "smart" are closer to each other, while "astute" and "clumsy" diverge on the semantic spectrum. This intelligent discernment is critical for performing tasks such as retrieving information, making recommendations, or understanding user queries in a way that mirrors human comprehension.
Let’s take a break from theory and code everything we learnt until now:
The model I’ll use for word embeddings is Universal Sentence Encoder (USE), why? Well, because this model is designed to capture the meaning of the sentence or even paragraphs, not just individual words.
#load all the necessary libraries and model
from sklearn.metrics.pairwise import cosine_similarity
import seaborn as sns
import matplotlib.pyplot as plt
import tensorflow_hub as hub
module_url = "https://tfhub.dev/google/universal-sentence-encoder/4"
model = hub.load(module_url)
#defining a function for embedding
#the model outputs the vector in [[numbers]] format, hence return the [0] element
def embed(input):
return np.array(model(input))[0]
#random array of words for demo
words = ["king", "queen", "man", "woman", "child", "throne", "palace", "water", "dog", "cat"]
#making a Dataframe where we can store the words and their respective embeddings
data={"words":words}
df = pd.DataFrame(data)
#apply the function to the words column
df['Embed'] = df['x'].apply(lambda x: embed([x]))
#compute similarity of each word to every other word and plot it to visualize the similarity
cosine_similarities = cosine_similarity(df["Embed"].tolist(),df["Embed"].tolist())
df_similarities = pd.DataFrame(cosine_similarities, index=words, columns=words)
plt.figure(figsize=(14, 12))
sns.heatmap(df_similarities, annot=True, fmt=".2f", cmap="coolwarm")
plt.show()
The output:
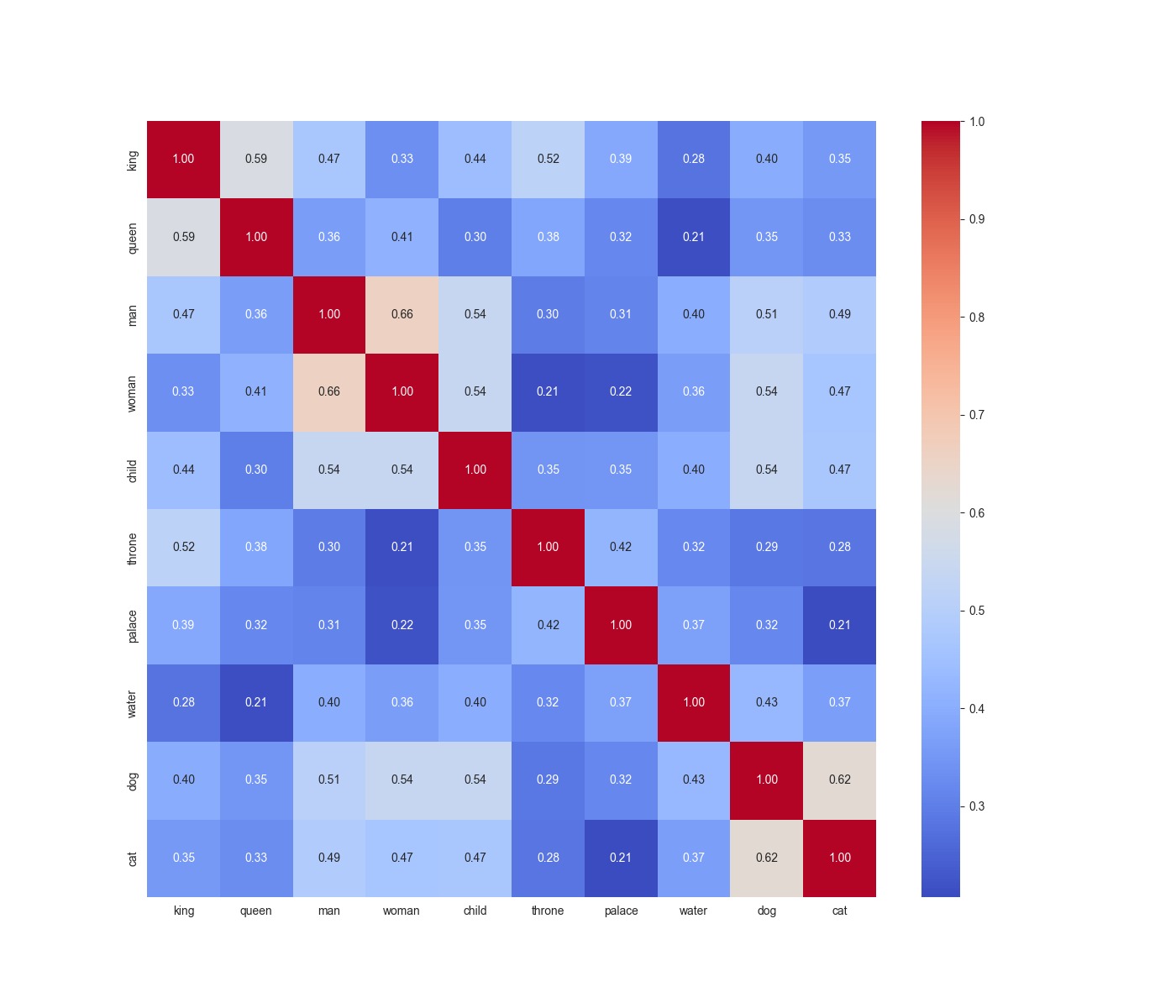
Pretty cool right? You can see king and queen has a high cosine similarity whereas king and water is relatively low in terms of similarity.
Let’s look at another example with sentences. The code used is the exact same.
sentences = ["I have a cute dog.", "Your age?", "My dog is 3 years old", "I am going to the mall", "I want to watch a movie", "This music is great", "I love eating strawberries.", "I detest aubergine", "I'm talking to my friend", "I'm going bird watching."]
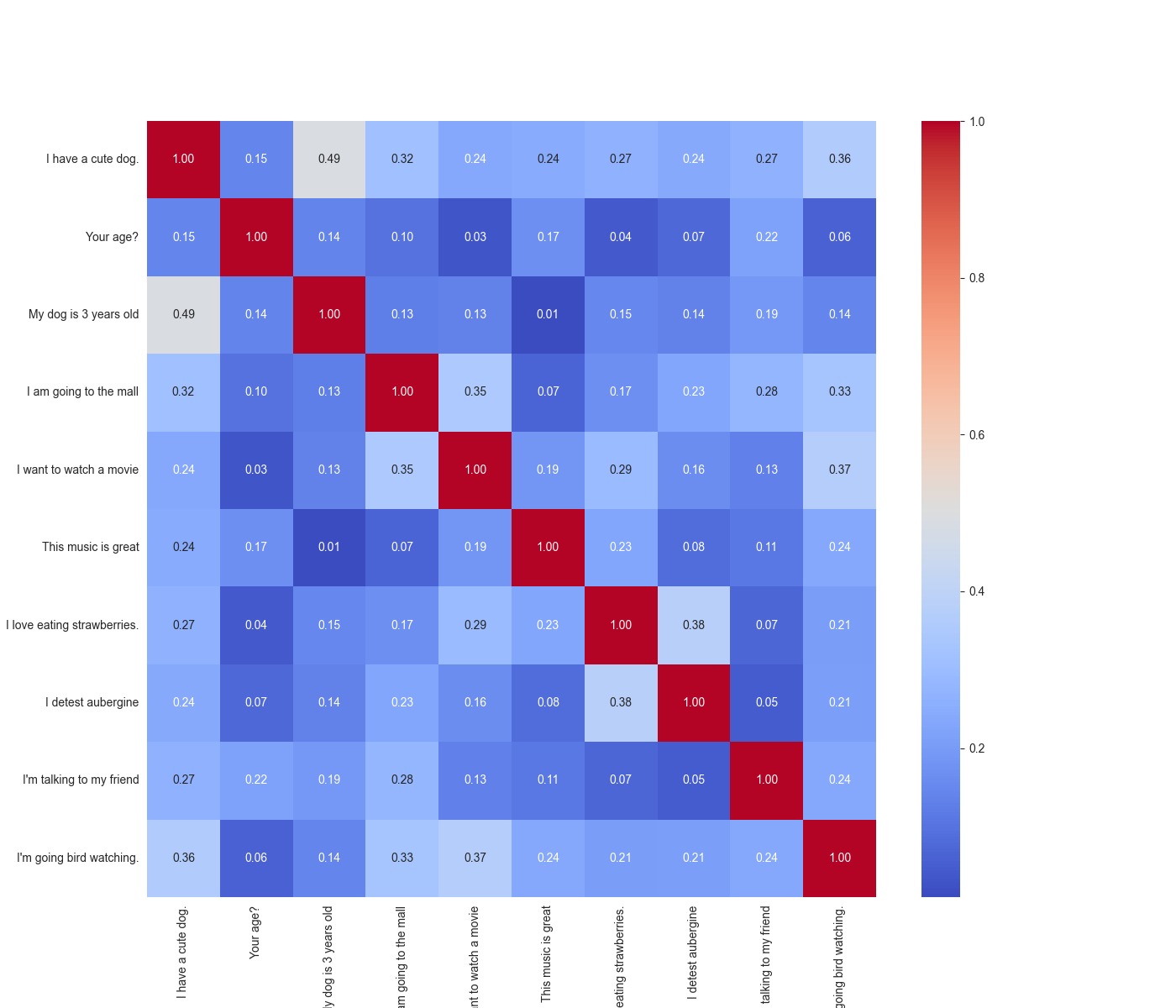
In this first installment of our two-part series on building a vector database, we've peeled back the layers of vector embeddings and their crucial role in powering generative AI. From the transformation of text into a numerical form that AI can grasp to the application of cosine similarity that allows for nuanced semantic searches, we've covered the foundational elements that give AI a memory-like capability.