AI SIMPLY EXPLAINED
All You Need To
Know About AI
Vector Databases Implementation: Part Two
This is Part 2 in a two-part series of how to build your vector database from scratch. So, if you have doubts regarding any concepts discussed in this article, you can refer to Part 1 which delves into the underlying concepts.
In the previous article of our series, we embarked on a fascinating exploration of vector embeddings, the transformative process that converts the chaos that is human language into the numerical language of AI. We delved into how these embeddings enable semantic search through the concept of cosine similarity, providing a way for generative AI like ChatGPT to access a form of memory, enhancing its responses with depth and accuracy.
Unstructured Databases and Vector Databases
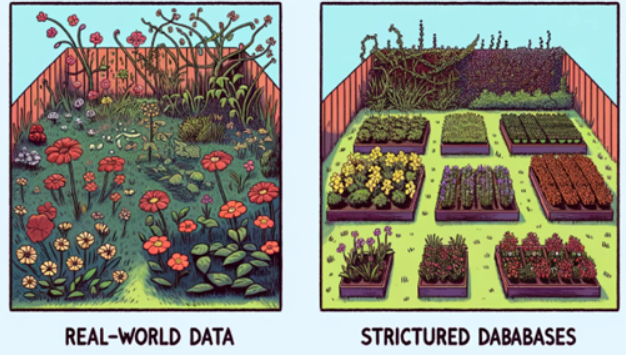
Structured datasets, neatly organized in tables and charts, are the staple of traditional databases. But much like a wild garden, real-world data is often unstructured - a chaotic mix of texts, images, audio, and videos that do not fit neatly into the rows and columns of structured databases. Vector databases thrive in this environment, making sense of the unstructured with their ability to comprehend and categorize the essence of data. It provides a flexible schema that can adapt to the data's inherent variability. This flexibility is paramount for AI, which must process and interpret a wide range of data types and structures.
Vector databases, a subset of unstructured databases, are not only adept at handling unstructured data but are also optimized for operations on vector embeddings. They understand and relate to the information store, much like an experienced archivist who knows where every document is and what it contains.
By storing data in the form of vectors, these databases allow for efficient similarity searches. They leverage indexing techniques to accelerate the retrieval of semantically similar items which is at the heart of many AI applications, because AI needs to interpret the meaning behind data to make decisions. Making vector databases ideal for tasks such as recommendation systems, image recognition, and natural language processing.
The Magic: Coding
Let’s get into it and code it all out.
First we’ll straighten out all the necessary functions and then dive into an example dataset.
The Start
# Importing necessary libraries
import pandas as pd
import numpy as np
#loading a pre-trained model for vector embeddings
import tensorflow_hub as hub
#for presentation
import matplotlib.pyplot as plt
import seaborn as sns
Creating the model for embeddings
# Loading the Universal Sentence Encoder
module_url = "https://tfhub.dev/google/universal-sentence-encoder/4"
model = hub.load(module_url)
# Define a function for creating embeddings using the model
def embed(input):
return np.array(model(input))[0]
Cosine similarity for vector embeddings
# Define a function to calculate cosine similarity
def cosine_similarity(A, B):
dot_product = np.dot(A, B) # The amount of 'overlap' between A and B
norm_A = np.linalg.norm(A) # The 'length' of vector A
norm_B = np.linalg.norm(B) # The 'length' of vector B
similarity = dot_product / (norm_A * norm_B) # The 'closeness' of A to B
return similarity
Querying our database
We can leverage the similarity function and query the database. Once we get a string input (our query), we convert it into an embedding and search all the other embedding against this particular embedding and find the closest and most similar embedding. We then sort the newly found similar embedding from the most similar to the least and output the “lim” most similar memories associated with those embeddings.
# A function to query the database for similar memories
def query(input, lim): #input is a string, lim is the n top similar matches you want to discover
i = embed([input])
df['similar'] = df['Embed'].apply(lambda x: cosine_similarity(x, i))
result=df.sort_values(by="similar", ascending=False)['Activity']
return result.head(lim)
This is like asking, "Which recipes in my cookbook taste like this new dish I've discovered?" We find the 'taste' (embedding) of our new dish, compare it to every recipe in our cookbook using our similarity score, and pick out the most similar ones.
In essence, this code snippet demonstrates how a vector database can store and retrieve information based on the semantic meaning of text, rather than just the literal text itself. The Universal Sentence Encoder is key in this process, turning sentences into vectors that the AI can understand and compare, much like converting complex flavors into a simple numeric scale that tells us how similar two dishes are.
Let’s make an example dataset that of some memories:

# create a new set of data to represent a person's routine and observations
data = {
'Timestamp': [
'2023-03-13 08:00:00', '2023-03-13 08:30:00', '2023-03-13 09:00:00',
'2023-03-13 09:30:00', '2023-03-13 10:00:00', '2023-03-13 10:30:00',
'2023-03-13 11:00:00', '2023-03-13 11:30:00', '2023-03-13 12:00:00',
'2023-03-13 12:30:00', '2023-03-13 13:00:00', '2023-03-13 13:30:00',
'2023-03-13 14:00:00', '2023-03-13 14:30:00', '2023-03-13 15:00:00',
'2023-03-13 15:30:00', '2023-03-13 16:00:00', '2023-03-13 16:30:00',
'2023-03-13 17:00:00', '2023-03-13 17:30:00'
],
'Activity': [
'Alex wakes up and stretches', 'Alex enjoys a hearty breakfast', 'Alex starts working on the computer',
'Alex takes a short coffee break', 'Alex attends a team meeting', 'Alex reads industry news',
'Alex prepares a light lunch', 'Alex reviews project timelines', 'Alex joins a client call',
'Alex responds to emails', 'Alex goes for a quick walk', 'Alex brainstorms with colleagues',
'Alex works on a presentation', 'Alex has a snack', 'Alex wraps up work',
'Alex heads out for an evening jog', 'Alex cooks dinner', 'Alex relaxes with a book',
'Alex plans the next day', 'Alex goes to sleep'
]
}
#create a df for the data and create a column for the respective embeddings
df = pd.DataFrame(data)
df['Embed'] = df['Activity'].apply(lambda x: embed([x]))
#query away now
query("relaxing", 5)
You can even try querying in the mini application running on this webpage right here. Try querying “relaxing” or “exercising” or anything else with a random limit, let’s say 5.
Hope you liked the article! Until the next one then. *bowing*
